
慕课中国课程热度分析

目录


分析背景及目的


分析思路及过程
一、提出问题


关键指标:课程热度、课程数量、完课率
该网站作为一个收录其他慕课平台课程的导航网站,仅仅爬取其课程列表缺少用户端的信息,所以对于该数据集仅能对课程的构成、分布、热度进行分析。


二、理解数据
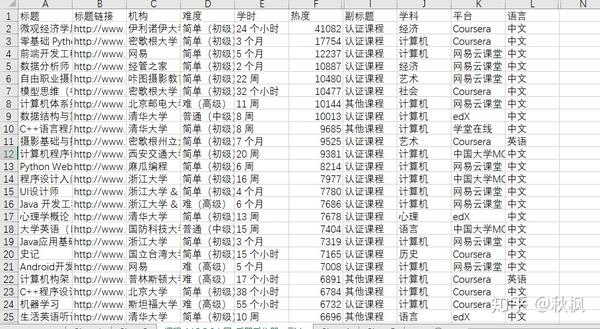
采用后裔采集器爬取了 慕课中国网站的课程列表,该数据集共11个字段(标题、标题链接、机构、难度、学时、热度、语言、开课时间、副标题、学科、平台),1609条记录。
文件地址: 课程-MOOC中国-后羿采集器.csv 提取码:m3ov
原始数据集为 csv 格式,将其另存为 xlsx 格式,使用 Excel2016 进行分析。如图:

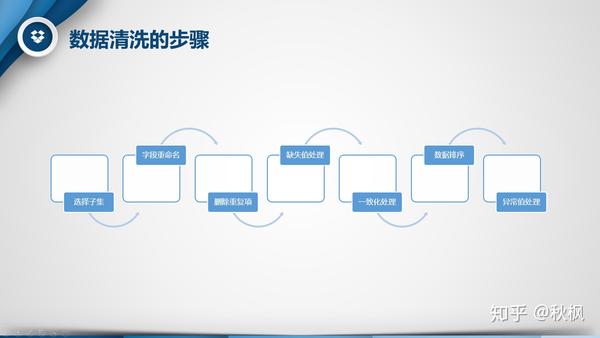
三、数据清洗

1、选择子集
部分课程每年多次开课或者自主学习,所以开课时间字段缺失值较多,并且与研究目标关系不大;
学时字段单位不统一,通过查询平台网站以月、周为单位的课程仅给出了推荐学时范围而且差异较大,无法总体对比,所以将这两个字段隐藏,不作为本次分析的对象。
2、字段重命名
为方便理解,收集数据时已经将字段名称进行了修改。
3、删除重复项
标题链接字段为该数据集中每条记录的唯一标识,对其进行重复项检查及删除。

采集数据时已做了一定处理,课程没有重复项。
4、缺失值处理
经过检查,只有副标题字段有缺失值且缺失值较多。该字段是各课程平台提供认证证书或者就业推荐的职业技能课程(肯定是收费课程了),如网易云课堂的微专业、Coursera的专项课程、Udacity的纳米学位等,将其统一修改为”认证课程“,而缺失值填入“其他课程”作为标记。


5、一致化处理
- 机构字段为教授该课程的大学、公司或者个人,少部分课程有多个机构共同授课,可不做处理。
- 热度字段中使用“查找和替换”将热度二字替换掉,并使用分列功能将其格式转换为常规。


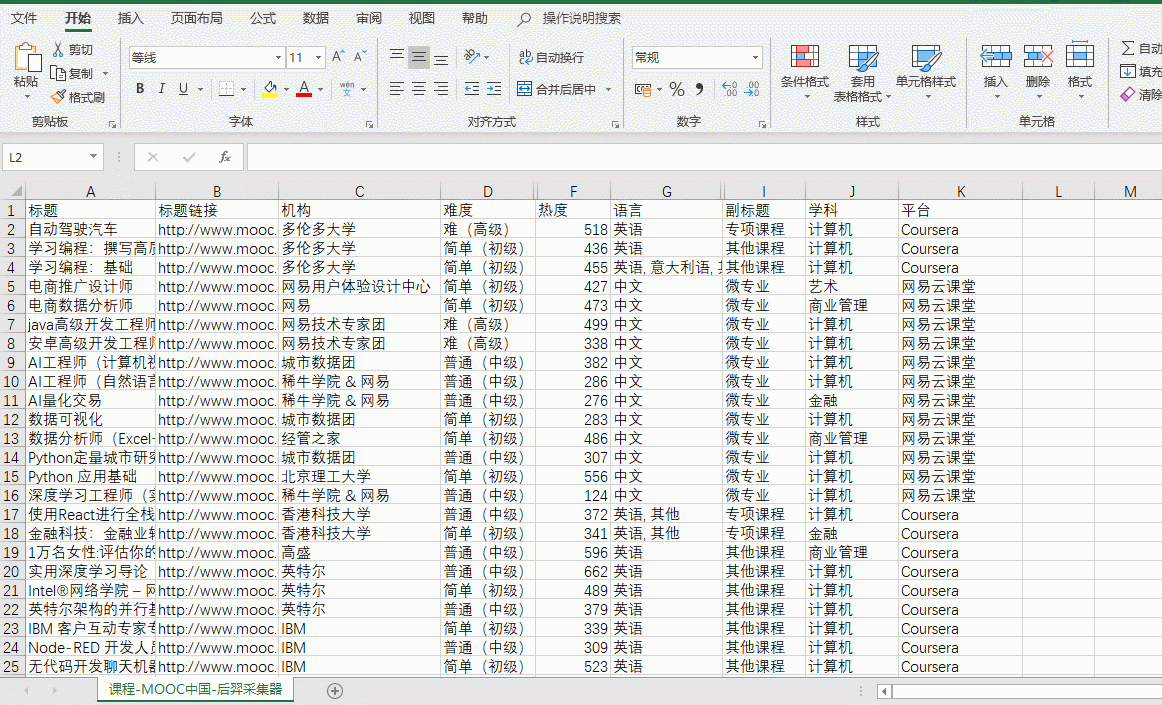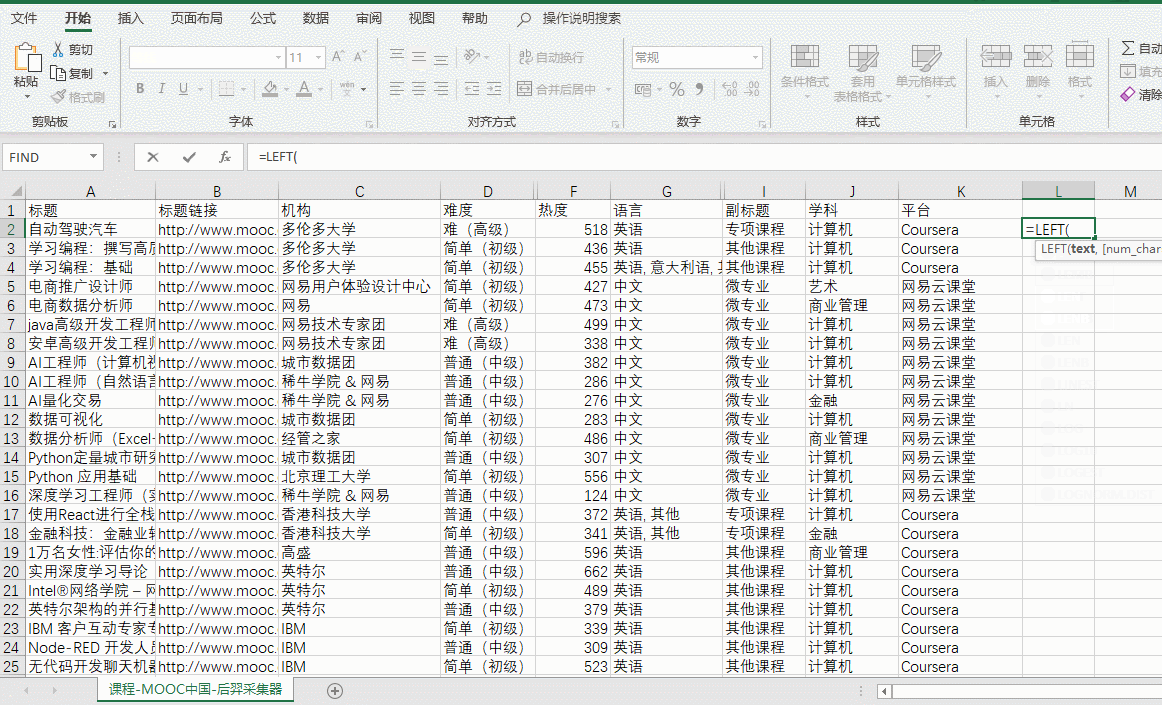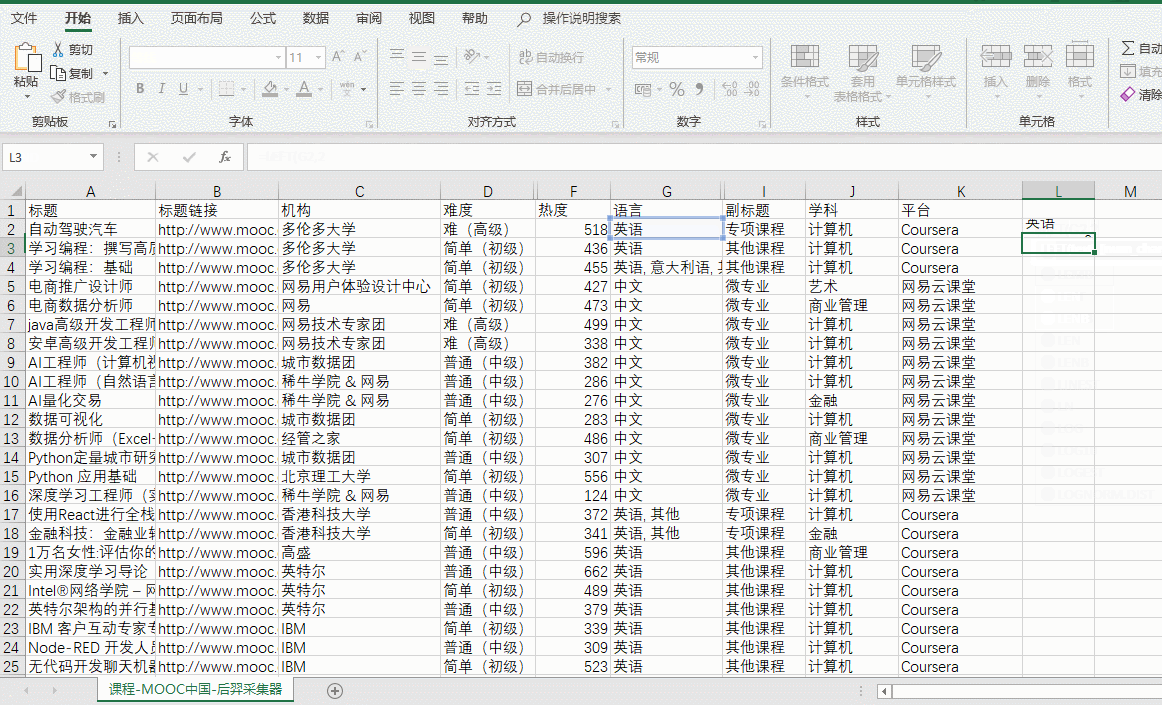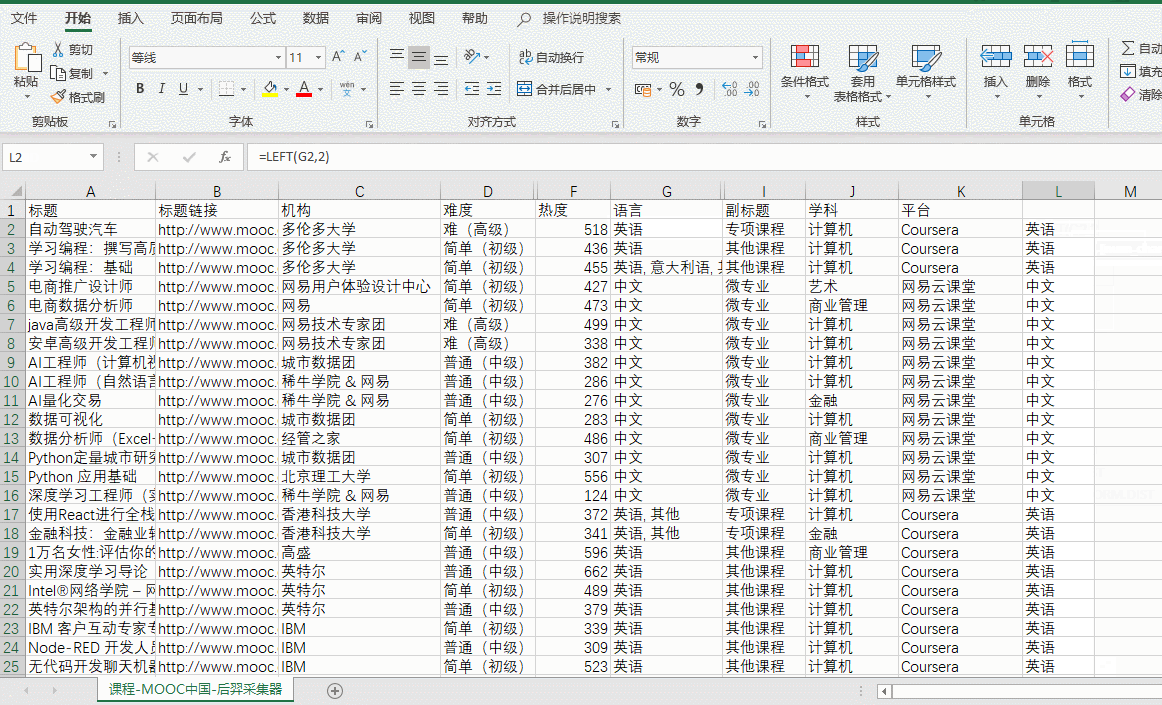
- 语言字段中,部分国外平台的课程有多种语言的字幕,使用函数截取其第一语言作为分析对象。

6、异常值处理 通过筛选发现平台字段中有一条“中国MOOC平台”的记录,经确认之后将其修改为“中国大学MOOC”。
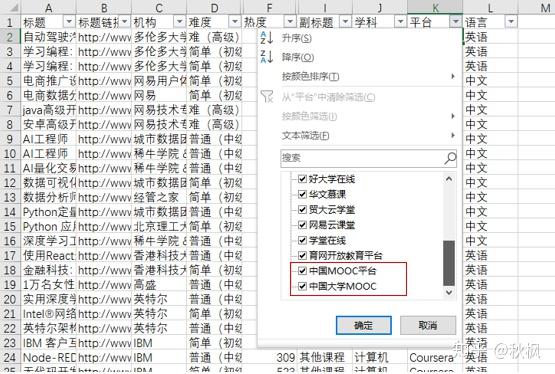

四、建立模型、得出结论
构建数据透视表,通过变换行列标签对课程数、课程热度进行对比分析。
1、该网站收录自哪些平台、机构的课程的较多?
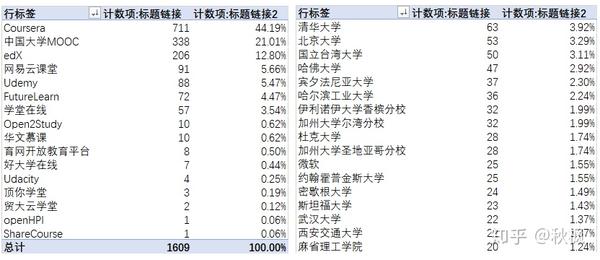

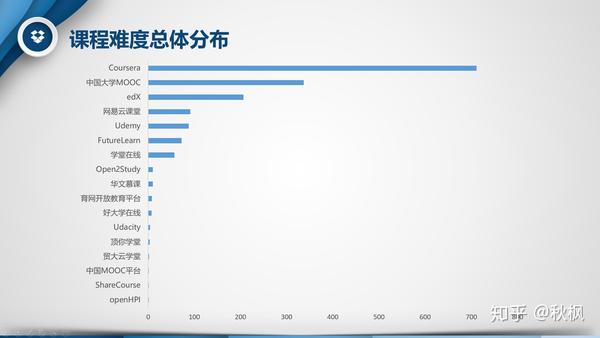

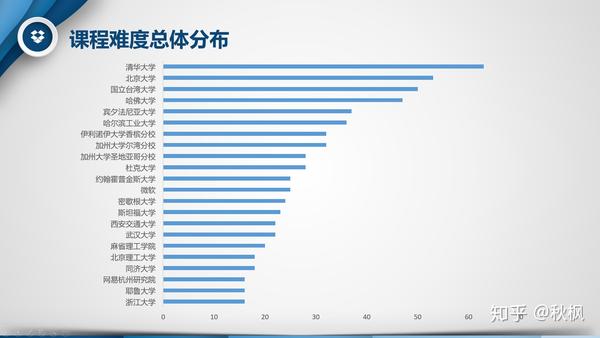

分别将平台和机构作为行标签,对标题链接的计数项倒序排列,可以看出来慕课中国所收录的课程相对集中在Coursera、中国大学MOOC和edX,而Coursera的课程数量相当夸张,占到了总数的44.19%,处于绝对的领先位置;教育机构中清华大学的课程则是最多的,不过领先优势相对较小。
2、课程难度高低的分布情况如何?
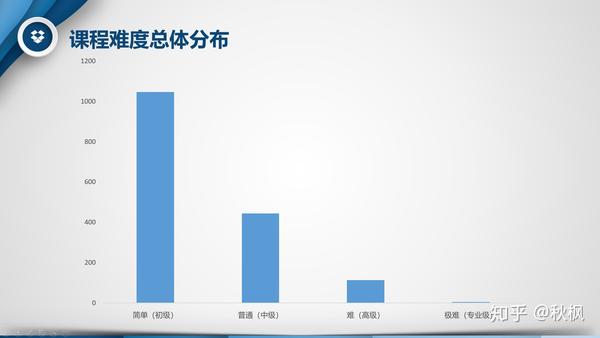


所有课程的难度分为简单(初级)、普通(中级)、难(高级)和极难(专业级)四个层级,上图为各难度层级中课程的数量,很明显简单(初级)的数量远远大于其他难度更高的课程。这也比较符合慕课平台的特点,如果课程难度过大,在线学习可能会有很多疑问难以解答,学习就很难坚持下去,所以多数课程主要时教授基础知识或者某一项技能。
3、受欢迎的课程有哪些特点?
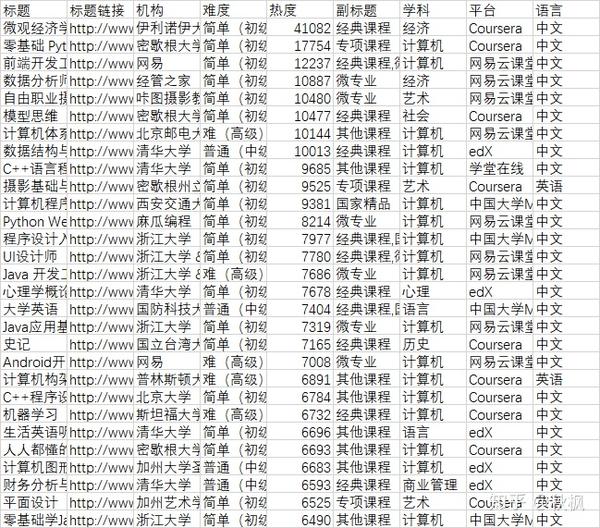

将热度字段倒序排序,截取热度前5%(81条记录)的课程数据(如图),对比不同难度、学科、平台、机构、语言及副标题的情况下课程数量的多少。经对比分析:
- 语言:只有中文和英文,毕竟是慕课中国,中文肯定最容易接受。
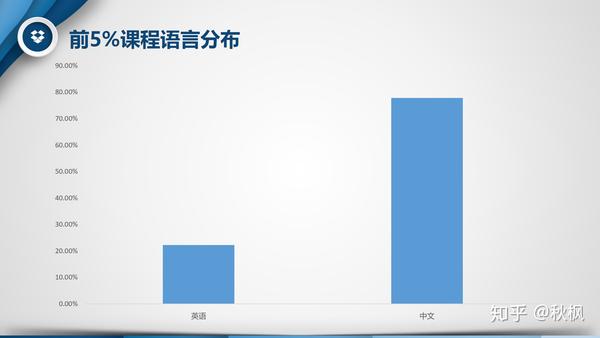

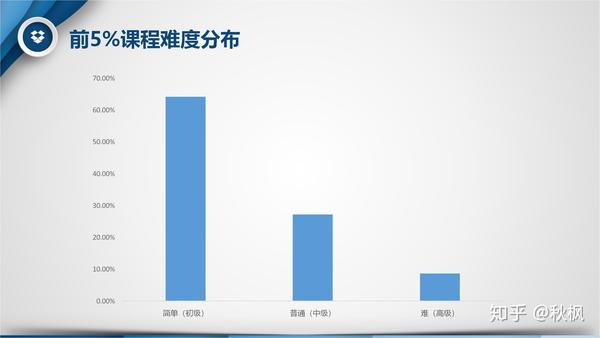
- 难度:依然是以简单(初级)为主,超过六成。

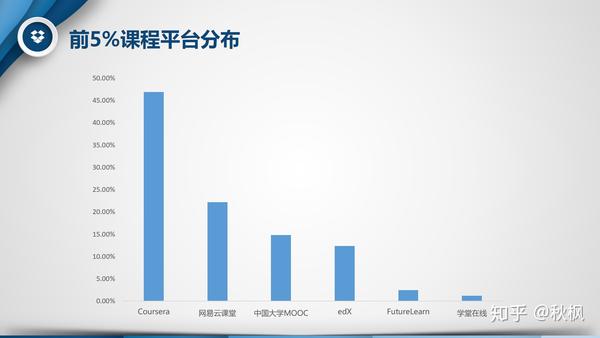
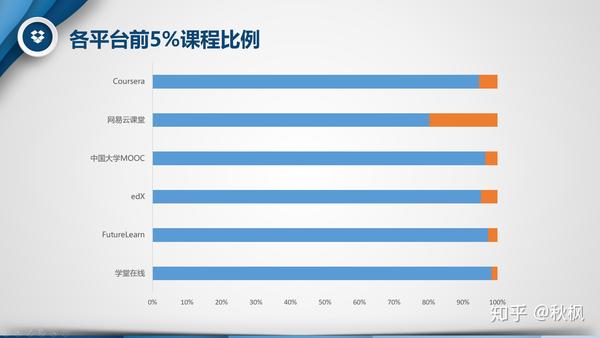
- 平台:来自Coursera的课程超过半数,不过相对于该平台高达711的课程总数,入选前5%的课程仅有5.3%,远低于网易云课堂的19.8%,可能这就是地头蛇吧。


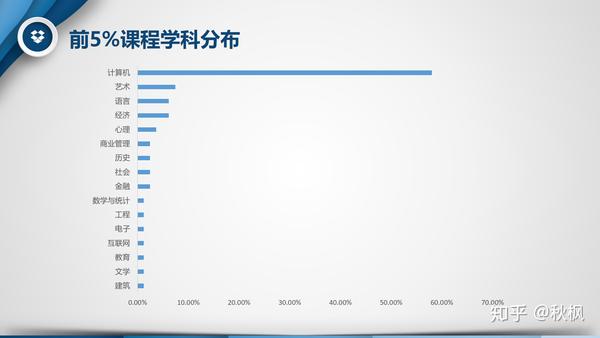
- 学科:计算机学科独占鳌头,接近六成的占比。

- 机构:相对分散,共有43个机构,最多的北京大学9.88%。
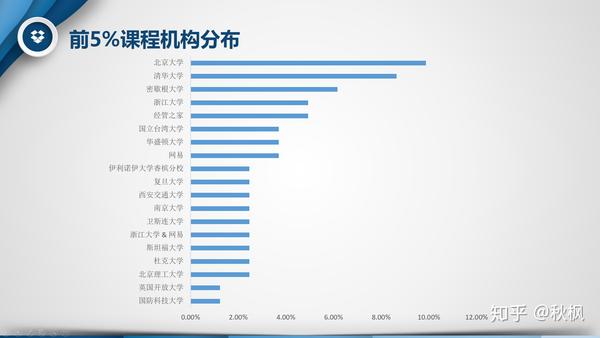
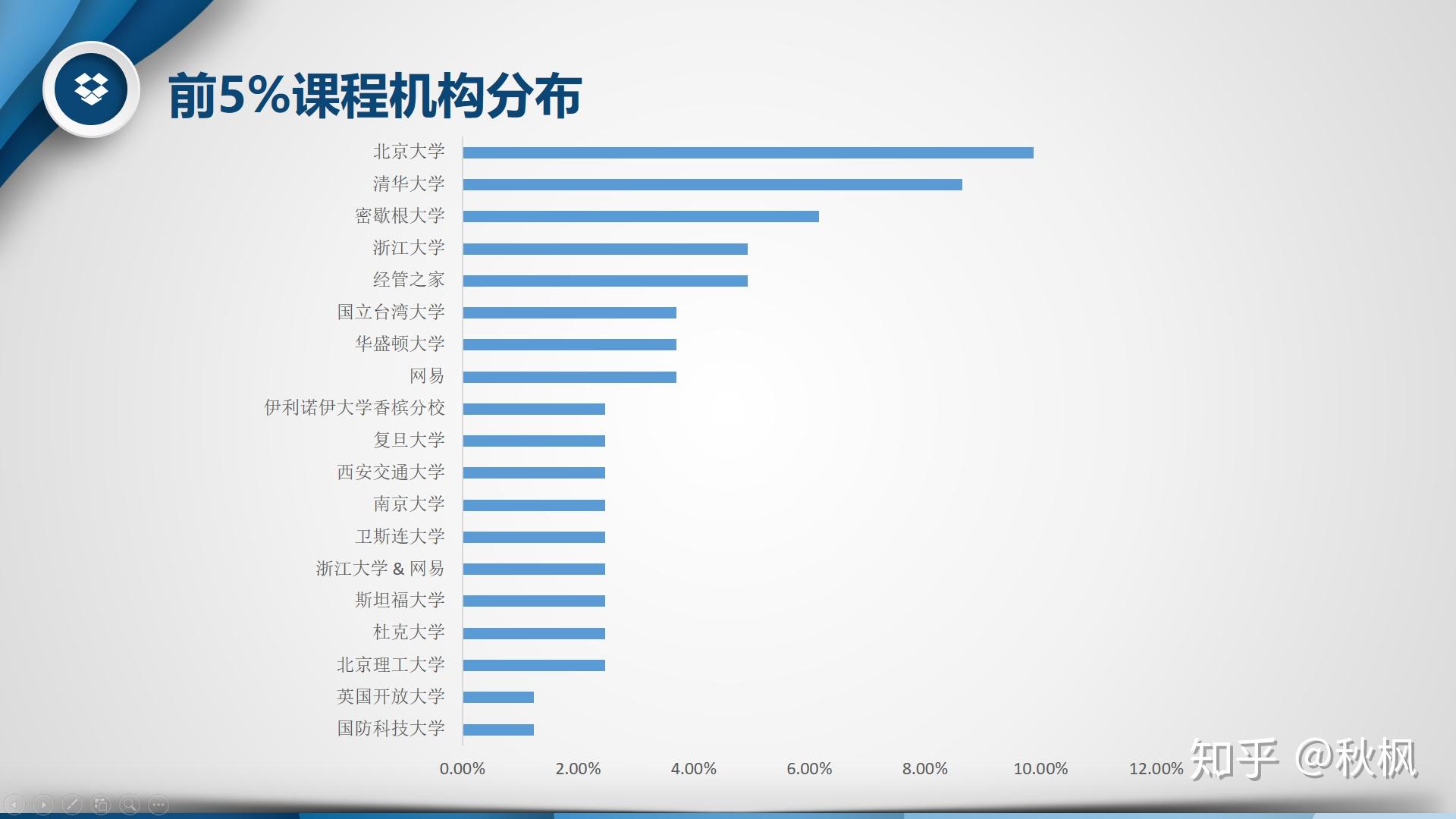
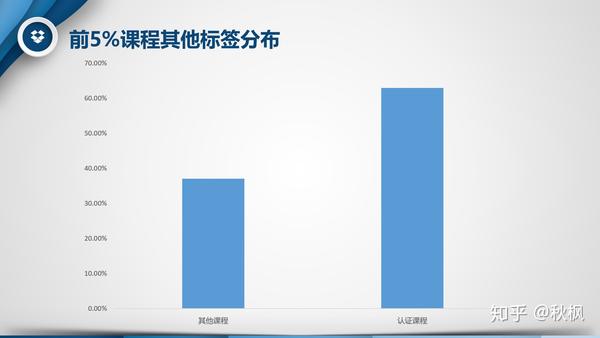
- 副标题:加了头衔的“认证课程”占据62.96%,这部分课程多为收费课程,并且给予认证甚至对接就业,目的性较强学习时间安排也比较紧凑,所以更受欢迎。

综上,慕课中国网站收录的1609个课程中,难度不要太大、计算机学科的、来自网易云课堂或者Coursera的中文课程(起码有中文字幕),可能会比较受欢迎。
分析结论及建议


文章被以下专栏收录
